Equivariant Diffusion Policy
Abstract
Recent work has shown diffusion models are an effective approach to learning the multimodal distributions arising from demonstration data in behavior cloning. However, a drawback of this approach is the need to learn a denoising function, which is significantly more complex than learning an explicit policy. In this work, we propose Equivariant Diffusion Policy, a novel diffusion policy learning method that leverages domain symmetries to obtain better sample efficiency and generalization in the denoising function. We theoretically analyze the SO(2) symmetry of full 6-DoF control and characterize when a diffusion model is SO(2)-equivariant. We furthermore evaluate the method empirically on a set of 12 simulation tasks in MimicGen, and show that it obtains a success rate that is, on average, 21.9% higher than the baseline Diffusion Policy. We also evaluate the method on a real-world system to show that effective policies can be learned with relatively few training samples, whereas the baseline Diffusion Policy cannot.
Introduction
Equivariance in Diffusion Policy
The recently proposed Diffusion Policy uses a sequence of denoising operations to generate robot actions.

We discover that the denoising process inherits the symmetries that exist in the policy function: a rotated state and initial noise should result in a rotated noise-free action.
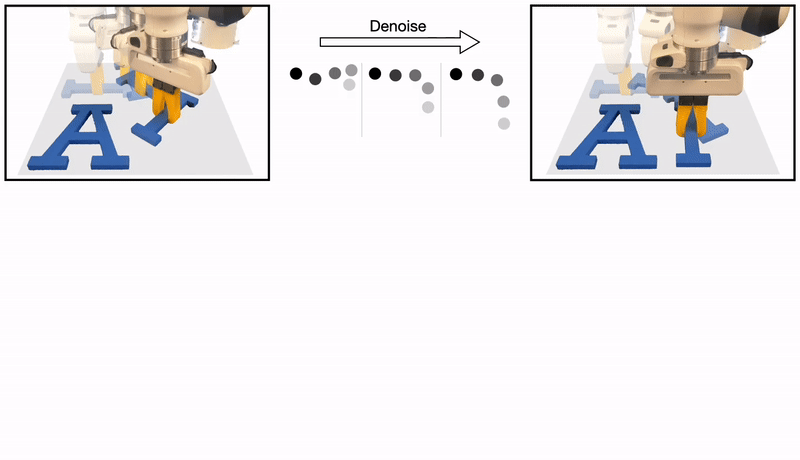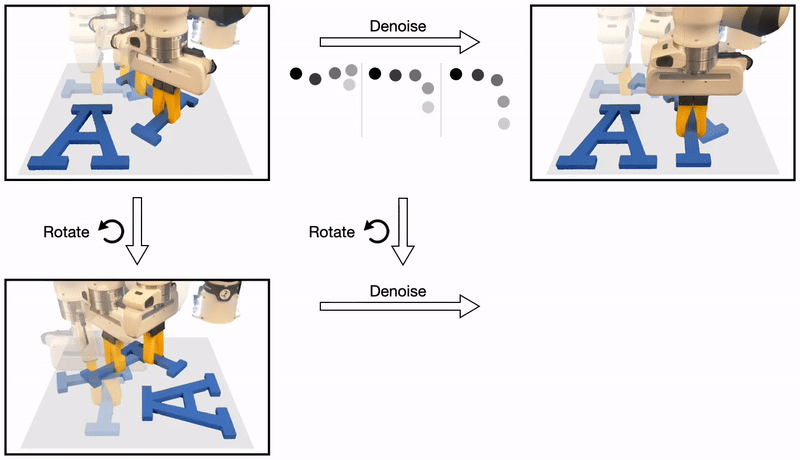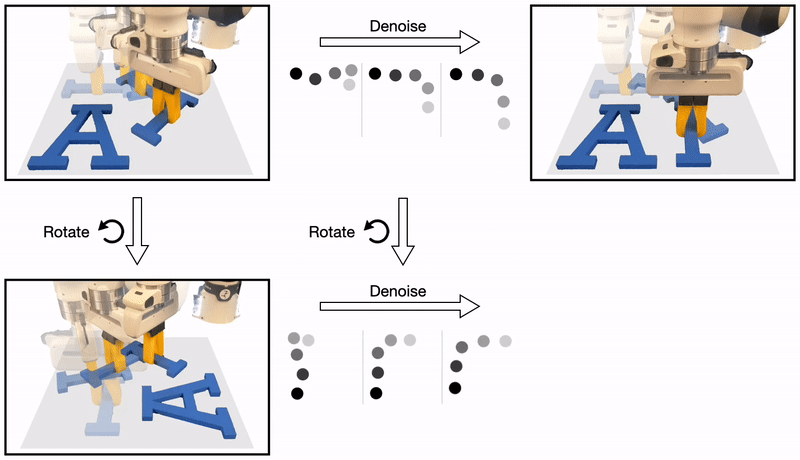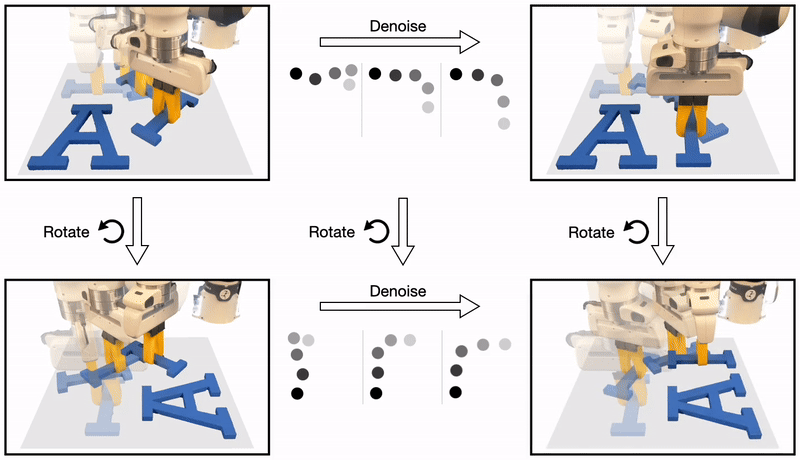
Formally, we show that whenever the policy is equivariant, the denoising function is also equivariant.

In this work, we leverage this symmetry to dramatically improve the sample efficiency in diffusion policy.
SO(2) Group Action on SE(3) Pose
We further analyze how an SO(2) group element acts on a 6DoF SE(3) pose in both absolute pose control and relative pose control.
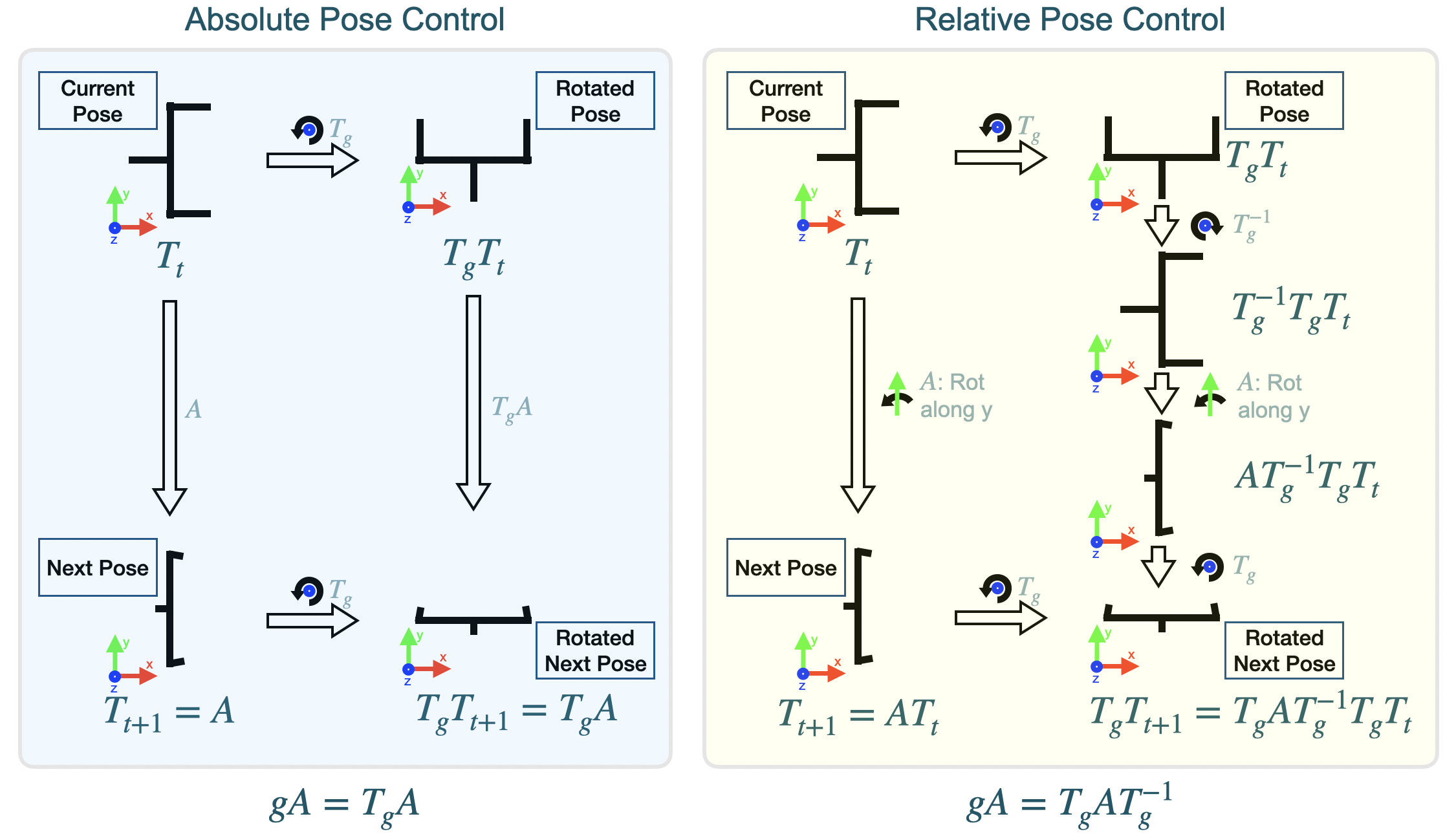
We also show how to decompose the above SO(2) group action into irreducible representations so that we can enforce the symmetry using an equivariant neural network. Please refer Section 4 of our paper for details.
The recently proposed Diffusion Policy uses a sequence of denoising operations to generate robot actions.
We discover that the denoising process inherits the symmetries that exist in the policy function: a rotated state and initial noise should result in a rotated noise-free action.
Formally, we show that whenever the policy is equivariant, the denoising function is also equivariant.
In this work, we leverage this symmetry to dramatically improve the sample efficiency in diffusion policy.
We further analyze how an SO(2) group element acts on a 6DoF SE(3) pose in both absolute pose control and relative pose control.
We also show how to decompose the above SO(2) group action into irreducible representations so that we can enforce the symmetry using an equivariant neural network. Please refer Section 4 of our paper for details.
Simulation Experiments
We first evaluate our method on 12 MimicGen environments.
Stack
Stack Three
Square
Threading
Coffee
Three Piece Assembly
Hammer Cleanup
Mug Cleanup
Kitchen
Nut Assembly
Pick Place
Coffee Preparation
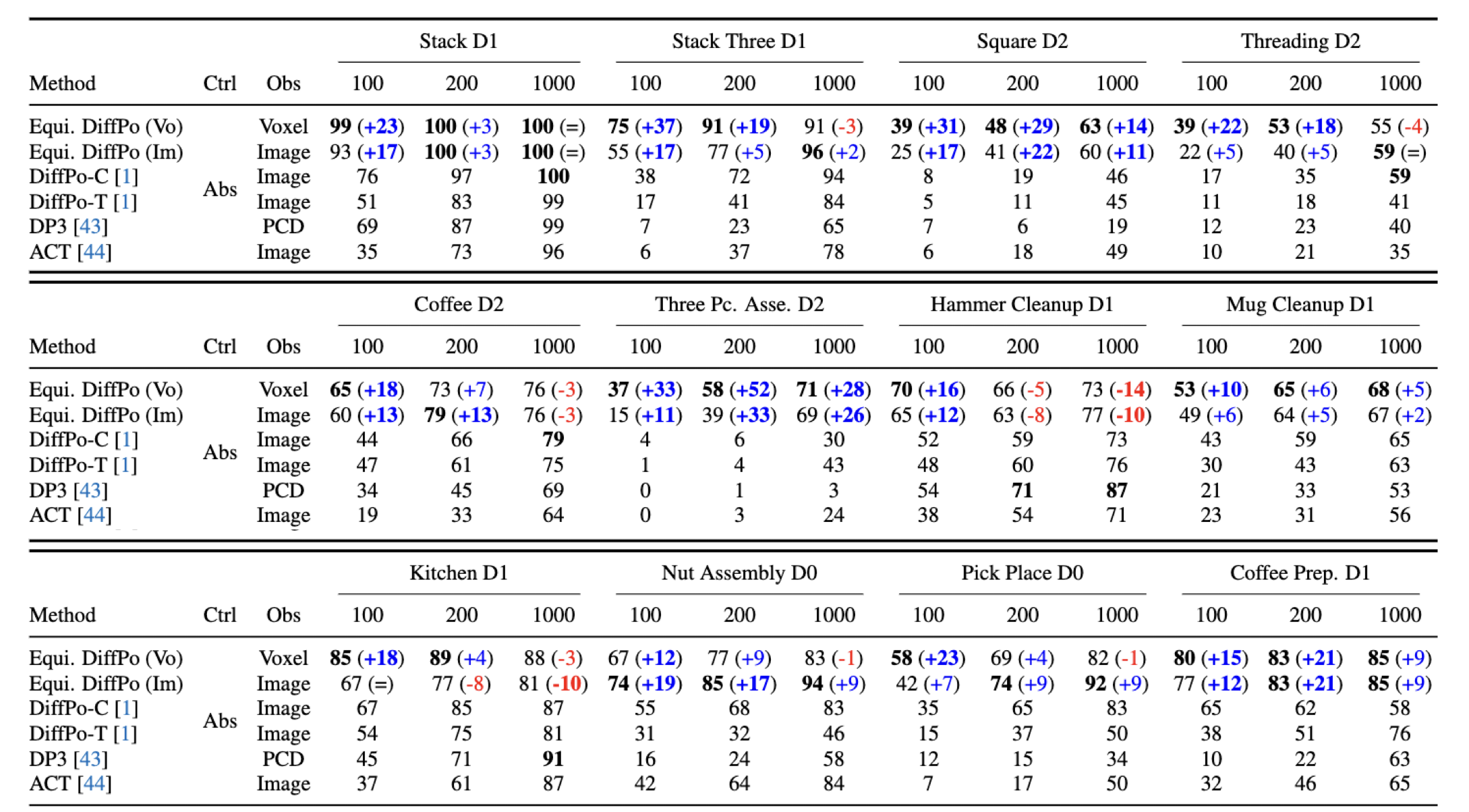
In most environments, our method significantly outperforms all baselines. Our method performs particularly well in the low-data regime (i.e., when trained with 100 or 200 demos).
Real-World Experiments
We further evaluate our method in six different real-world environments, where we show our method can learn to solve those tasks using less than 60 demonstrations.
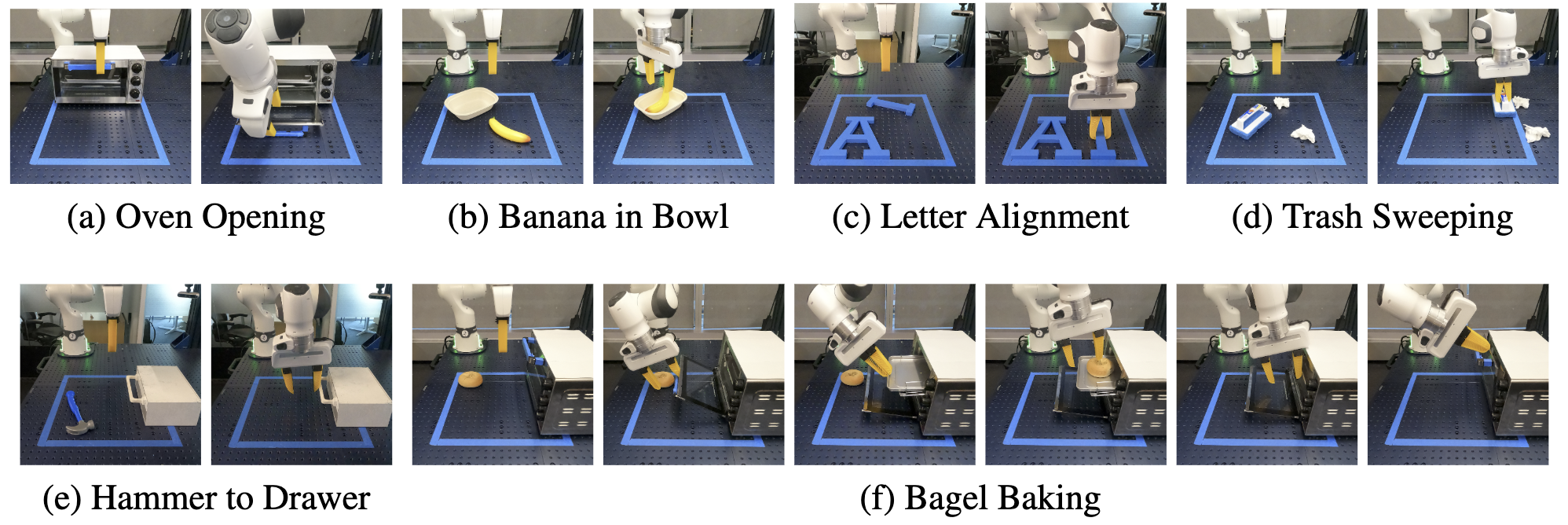
Bagel Baking
Hammer to Drawer
Banana in Bowl
Trash Sweeping

Video
Talk
Citation
@inproceedings{
wang2024equivariant,
title={Equivariant Diffusion Policy},
author={Dian Wang and Stephen Hart and David Surovik and Tarik Kelestemur and Haojie Huang and Haibo Zhao and Mark Yeatman and Jiuguang Wang and Robin Walters and Robert Platt},
booktitle={8th Annual Conference on Robot Learning},
year={2024},
url={https://openreview.net/forum?id=wD2kUVLT1g}
}